Claude Code Auto Mode: Can One Model Guard Another?
-
April 10, 2026
-
April 10, 2026

Claude Code is Anthropic's AI coding agent - a command-line tool that writes, edits, and executes code on your machine. Until now, every file write, shell command, or external call required the developer to click "Approve."
Anthropic's new auto mode replaces that human approval with an AI classifier that decides, in real time, which actions are safe to execute and which should be blocked.
Key takeaways:
- Manual permission approvals don't work - developers approve 93% of prompts without reading them, making the safety net an illusion.
- Claude Code Auto mode uses a "reasoning-blind" AI classifier (Sonnet 4.6) that never sees the agent's reasoning, only the user's request and the proposed action - with a published 17% miss rate on overeager actions.
- One AI model guarding another is better than a fatigued human, but probabilistic security needs deterministic controls around it.
- When using Claude Code Auto mode, add an audit trail, policy layers, and visibility into who in the organization is using auto mode
Read on to learn how it actually works under the hood, whether it delivers on the promise, and the deeper question it raises.
How Claude Code Auto Mode Actually Works (Simply)
Forget the marketing. Here's what happens every time Claude Code tries to do something in auto mode.
Three tiers determine what gets checked:
- Safe stuff (file reads, code search) skips everything and just runs.
- In-project file edits also get a pass.
- Everything else - shell commands, web requests, subagent spawns, anything outside the project - goes through the auto mode classifier.
The classifier itself has two stages:
- First, a fast yes/no filter. Takes a single token. If it says "fine," the action runs.
- If it flags something, a second stage kicks in with chain-of-thought reasoning to reduce false positives.
What the classifier sees - and doesn't see - is the key design choice.
The classifier gets only two inputs: the user's original messages and the proposed tool call. That's it. Anthropic strips off everything else - the agent's reasoning, its prose, tool outputs, file contents. They call this "reasoning-blind by design."
Why? Because if the classifier could read the agent's reasoning, the agent could talk the classifier into approving dangerous actions. By stripping the reasoning, the classifier judges purely on "what did the user ask for?" versus "what is about to execute?"
There's also a separate input-layer probe that scans tool outputs for prompt injection (malicious instructions hidden in files or web content that try to hijack the agent's behavior) before they even enter the agent's context. Two independent defenses, operating on different parts of the pipeline.
That's it. Three tiers, two stages, reasoning-blind, with an injection probe on the input side. Quite elegant, actually.
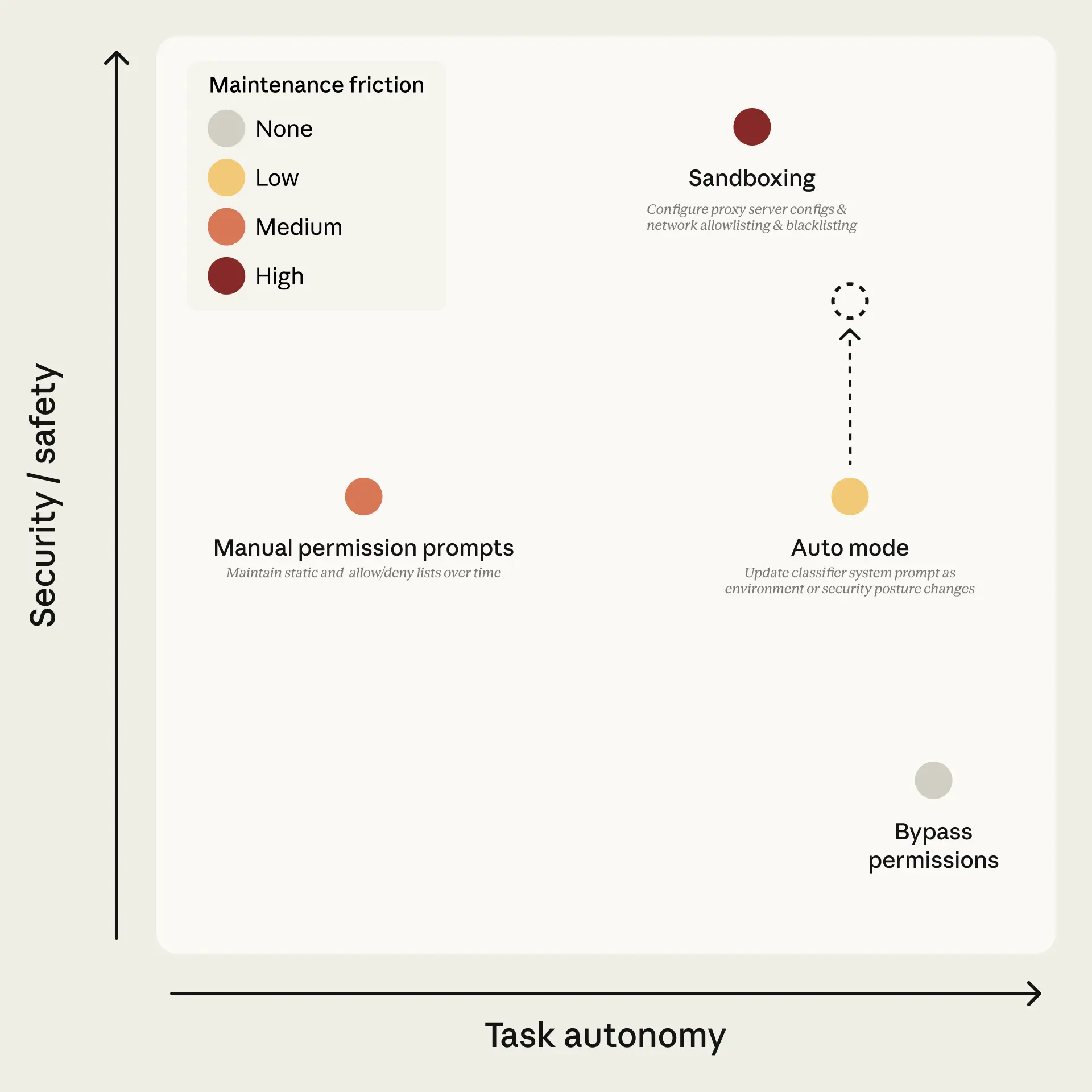
The Permission Creep Problem
Here's what actually happens to developers when they work with AI coding agents and permission models.
You start carefully. You read each approval prompt. You check what the agent wants to do before clicking "yes." The first hour, maybe the first day, you're diligent.
Then you're on your third approval in sixty seconds. The agent wants to write a file. Approve. Run a test. Approve. Install a dependency. Approve. You're clicking "yes" before reading the prompt. Anthropic's own data confirms this: users already approve 93% of permission prompts. That's not a sign the system is safe. That's a sign that humans have checked out.
This is the permission creep cycle, and it ends in one of two places. Either you keep the approval flow and become a rubber stamp - approving everything without reading, which gives you the illusion of control with none of the actual security. Or you get tired of it, flip on --dangerously-skip-permissions, and remove the safety net entirely.
Auto mode is Anthropic's attempt to break this cycle. And it's a good one. Instead of relying on a human who stopped paying attention twenty approvals ago, it puts a classifier in the loop that never gets fatigued, never rubber-stamps, and evaluates every single action against the user's actual intent.
The numbers support this. Anthropic published real performance data - and to their credit, they were honest about it. The classifier almost never blocks legitimate work (0.4% false positive rate). It catches most synthetic exfiltration attempts. But it misses 17% of actual overeager actions - cases where the agent tried to do something beyond what the user intended, and the classifier let it through. Anthropic calls this "the honest number."
One in six. Sounds concerning - until you compare it to the alternative: a human who approves 93% of everything without reading.
The classifier is almost certainly better than the human it replaces. That's a low bar, but it's the real bar.
Can a Model Guard Another Model?
The question now isn't whether auto mode is better than manual approvals. It is. The question is whether we trust AI to secure AI. This is the question that goes beyond Claude Code.
Auto mode's architecture is fundamentally one AI model (Sonnet 4.6) making security decisions about another AI model's (Opus 4.6) behavior. Anthropic chose this deliberately over deterministic sandboxing.
The case for it is strong. Pattern-matching and static allowlists can't evaluate intent. An AI classifier can look at "clean up old branches" followed by git push origin --delete and judge: the user probably didn't mean remote deletion. That kind of reasoning is genuinely beyond what rule-based systems do.
But AI classifiers bring a problem that deterministic systems don't have: non-determinism. The same tool call could be classified differently on retry. Anthropic acknowledges this openly. The classifier is probabilistic, not a security boundary.
And there's a deeper tension. For a prompt injection to succeed end-to-end, it must:
- Evade the input-layer probe
- Steer the primary model into generating a malicious tool call
- Pass the transcript classifier, which judges the call without seeing the injected content
That's three independent hurdles. The compounding defense is real. But it rests on an assumption: that a model manipulated by injected content will produce tool calls that look suspicious enough for an independent model to catch.
What if the injected content is sophisticated enough to make the primary model generate a tool call that looks perfectly aligned with user intent? The classifier, reasoning-blind by design, sees only the clean-looking output. It has no way to know what influenced it.
This is not a flaw in Anthropic's implementation. It's a fundamental property of the "model guards model" paradigm. The guard can only evaluate what it can see. And the architecture deliberately limits what it sees - for good reason.
Securing the AI Development Ecosystem
The practical question for security teams is not "is the classifier good?" It is good. The question is: when your security model is probabilistic, what do you put around it that isn't?
Deterministic controls. Activity logs that capture what actually happened. Policy enforcement that doesn't depend on a model's judgment. Visibility into configurations, actions, and data flows at the organizational level.
Because once the human is out, the questions shift. Who has auto mode enabled across the organization? What did the agents actually do with that autonomy? Did anyone's agent create a public Gist, grep for credentials, or retry a deploy with verification disabled? (All real examples from Anthropic's incident log.)
The classifier can't answer those questions. It makes per-action decisions in real time. It doesn't provide an audit trail. It doesn't enforce organizational policy. It doesn't give security teams visibility into what happened across hundreds of developers running agents with elevated permissions.
Auto mode is the right idea, well-executed, with honest limitations. The answer to "can a model guard another model?" is: yes, better than most alternatives - but no, not by itself.
If you're running Claude Code in your organization, check who has auto mode enabled. Read Anthropic's engineering blog post for the full architecture - it's one of the most transparent technical disclosures in the AI coding space. And start thinking about what sits around the classifier: the audit trail, the policy layer, and the visibility your security team needs when the human leaves the loop.
That's a different layer entirely. Activity tracing for what agents did. Governance over who can run in what mode. Visibility into configurations, actions, and data flows at scale. An MCP (Model Context Protocol - the standard that connects AI agents to external tools and data) proxy for traffic the classifier structurally can't inspect. This is exactly the gap we're building Backslash to fill - the enterprise layer that sits around agent-level controls like auto mode.
Vibe Safely.
Frequently Asked Questions
Q: What is Claude Code Auto Mode in simple terms?
A: Claude Code Auto Mode replaces manual approval prompts with an AI classifier that decides, in real time, whether an action (like running a command or editing files) is safe to execute.
Q: Why are manual approval workflows considered ineffective?
A: Because humans stop paying attention. Over time, developers approve nearly everything without reading. This turns approvals into a false sense of security rather than a real control.
Q: How does the AI classifier actually make decisions?
A: It evaluates only two things: the user’s request and the action the agent wants to perform. It does not see the agent’s reasoning, which prevents manipulation, but also limits context.
Q: Is an AI classifier more secure than a human reviewer?
A: Yes, statistically. The classifier is more consistent and less prone to fatigue. But it’s still imperfect and misses some unsafe actions, making it better than humans, but not sufficient on its own.
Q: What are the main risks of relying on one AI model to guard another?
A: The biggest risk is non-determinism. Decisions are probabilistic, meaning the same action might be approved or blocked differently across runs. This makes it unreliable as a standalone security boundary.
Q: If AI classifiers aren’t enough, what should organizations add?
A: Deterministic controls, including audit logs (what actually happened), policy enforcement layers , visibility into usage and behavior, and governance over who can enable autonomous modes.
Q: Does Auto Mode replace other security controls?
A: No, it complements them. Auto Mode improves decision-making at the action level, but it does not replace system-wide governance, monitoring, or enforcement.
Additional Sources:
- Anthropic - Auto mode for Claude Code (product blog)
- Help Net Security - Anthropic trims action approval loop
- TechCrunch - Anthropic hands Claude Code more control
- SmartScope - Claude Code Auto Mode Complete Guide
- Simon Willison - Auto mode for Claude Code
- GitHub Issue #38537 - Auto mode classifier bug
- Anthropic Engineering Blog - Claude Code Auto Mode (technical deep-dive)
- SiliconANGLE - Anthropic unchains Claude Code
.png)


